The Real Problem Is Not the File Size
Resumable video upload is often described as a network problem: split the file into chunks, retry failed chunks, and show a progress bar. That is a useful beginning, but it is not enough for a large media project. A browser-based video editor is not uploading a single anonymous blob. It is building the source of truth for future frame extraction, transcript generation, AI analysis, media provenance, collaboration, export, and repair. Upload a real shoot
The file size is only the most visible pressure. The harder problem is continuity. A creator may select five long clips, start editing while lightweight artifacts are still processing, refresh the tab, move to a different network, lose permission to a local file handle, or hit a codec path that works on the server but not in the browser. A simple upload request cannot explain those states. A product-grade architecture has to preserve enough state for the system and the user to recover.
VibeChopper treats upload as the front door to the media pipeline. The product already tracks upload sessions, per-file progress, telemetry samples, resumable browser artifacts, original-file upload progress, server repair state, frame and transcript readiness, and media summaries. The same principles generalize into a resumable video upload architecture for any large media project: keep local recovery separate from server truth, make every file independently observable, make final commit idempotent, and connect uploaded bytes to editor-facing media records.
That last piece is important. The upload is not done merely because object storage contains a file. It is done when the editor can use the file safely: the user owns it, the project references it, derived artifacts can be created or repaired, progress can be explained after refresh, and future render or AI workflows know where the source came from.

Resumable upload architecture turns unreliable networks and browser limits into explicit, recoverable product state.
Start With Architecture Boundaries
A clean resumable upload design has four boundaries. The browser owns local file access and temporary artifacts. The upload session API owns authenticated progress state. Object storage owns durable bytes. The media graph owns product meaning: this source file belongs to this user, this project, this video record, this transcript, these frames, and later this render. Explore your media graph
The browser boundary is constrained by platform rules. Web apps cannot assume they can reopen a local file after a refresh. Some browsers support File System Access handles and OPFS, some do not. Storage quota can be limited. Persistence may require user or browser permission. That means browser resume logic should be capability-aware instead of magical. It should store manifests and reusable artifacts where possible, store handles where allowed, and present a clear reselect-file path when the platform requires the user to restore access.
The upload session boundary is the durable control plane. It should be user-scoped and project-scoped, with device context, status, heartbeat time, file rows, per-stage progress, error state, and completion metadata. The browser can reconnect and ask, what does the server know about this upload? Other product surfaces can watch progress without scraping component state. Support and remediation flows can inspect structured fields instead of asking users to reconstruct what happened.
The object storage boundary should be boring and strict. The upload service should write bytes into project-owned paths or upload IDs that cannot collide across users. The client should not decide final storage paths by sending arbitrary destinations. The server should verify ownership, file identity, chunk manifests, checksum expectations, and commit state before promoting bytes into canonical media records.
The media graph boundary is where the upload becomes part of the editor. Once an original file is committed, the system can derive frames, audio, transcript, thumbnails, proxies, metadata summaries, and render inputs. Those derived assets should point back to the source. That provenance is what lets an AI editor explain an edit, repair a missing artifact, or render the final timeline from trusted inputs.
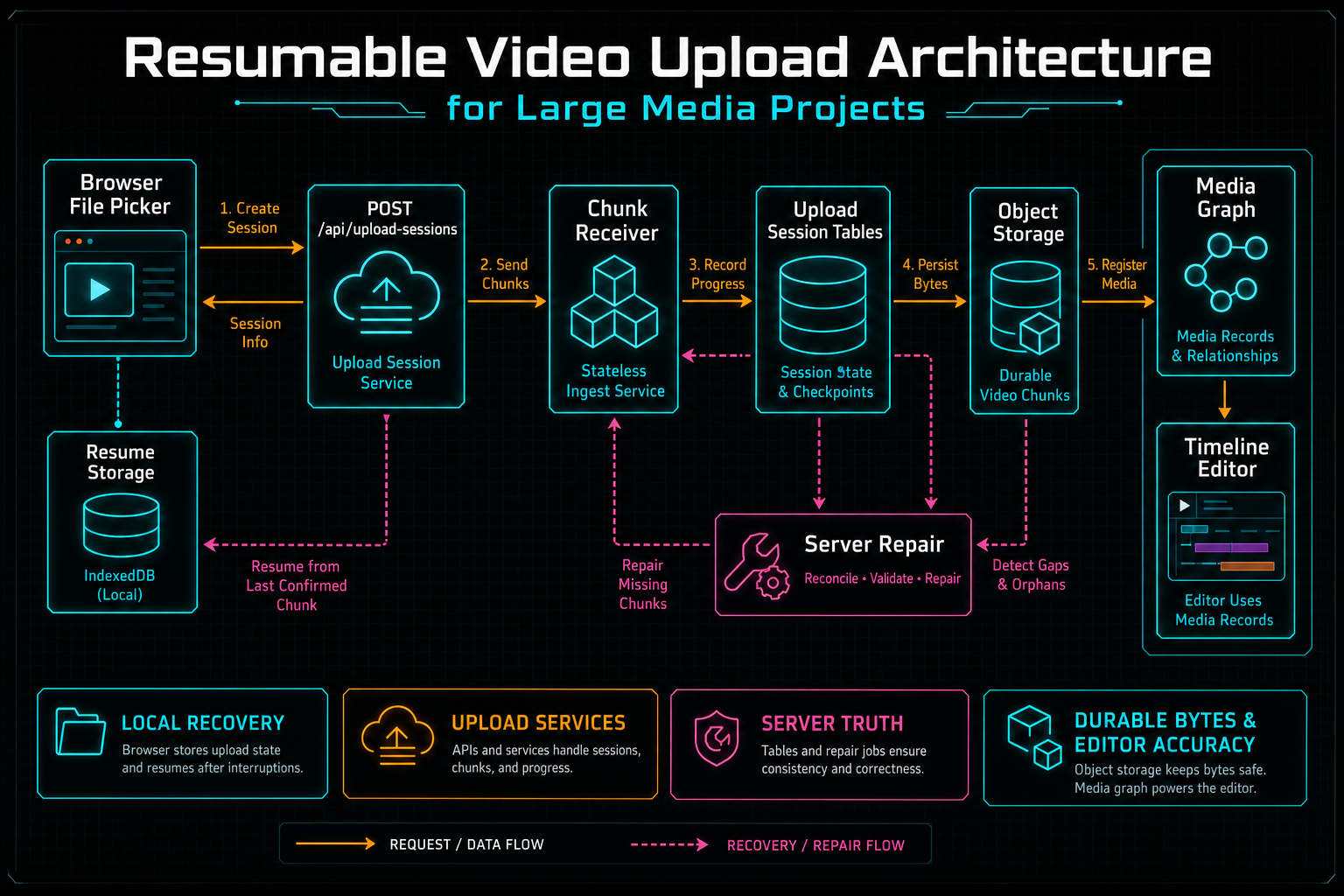
A reliable upload system separates local recovery, server truth, durable bytes, and editor-facing media records.
Model Upload Sessions as Product State
The most common resumable upload mistake is hiding all state inside the transport layer. A chunk library can remember byte ranges, but the product needs richer questions answered. Which project is this upload for? Which authenticated user owns it? Which files in the batch are complete? Which files are waiting on local permission? Which files have frames and transcripts ready even though original bytes are still moving? Which file is safe to retry? Upload a real shoot
An upload session gives those questions a durable home. At minimum, the session should include user ID, project ID, device session ID, device type, browser, operating system, network type, status, heartbeat time, file count, completed time, ended reason, and retention policy. Each session file should include local file ID, server video ID if available, file name, file size, MIME type, content hash when known, current stage, percent, transferred bytes, total bytes, last error, and stage-specific metadata.
The stage vocabulary should reflect the product, not just the transport. Useful stages include selected, hashing, preparing artifacts, uploading artifacts, uploading original, committing original, server repair, analyzing, complete, failed, and waiting for reselect. For a video editor, artifact stages matter because frames, audio, transcript, and metadata can be useful before the full original upload finishes. The UI should not collapse all of that into one opaque progress number.
A heartbeat is not decoration. It lets the server distinguish active work from abandoned sessions. A tab can disappear without sending a clean final message. A laptop can sleep. A mobile browser can suspend JavaScript. Heartbeats let the product mark a session stale while keeping enough state to resume or explain it later. The user sees a recoverable state instead of a vanished upload.
This model also helps with duplicate requests. If the same browser reconnects with the same project and device session, the server can reuse the active upload session instead of creating a new one. If a file row already exists for the same local ID, file name, size, or content hash, the server can update the record rather than fragmenting progress across duplicates. Idempotency begins in the data model, not in a retry loop.
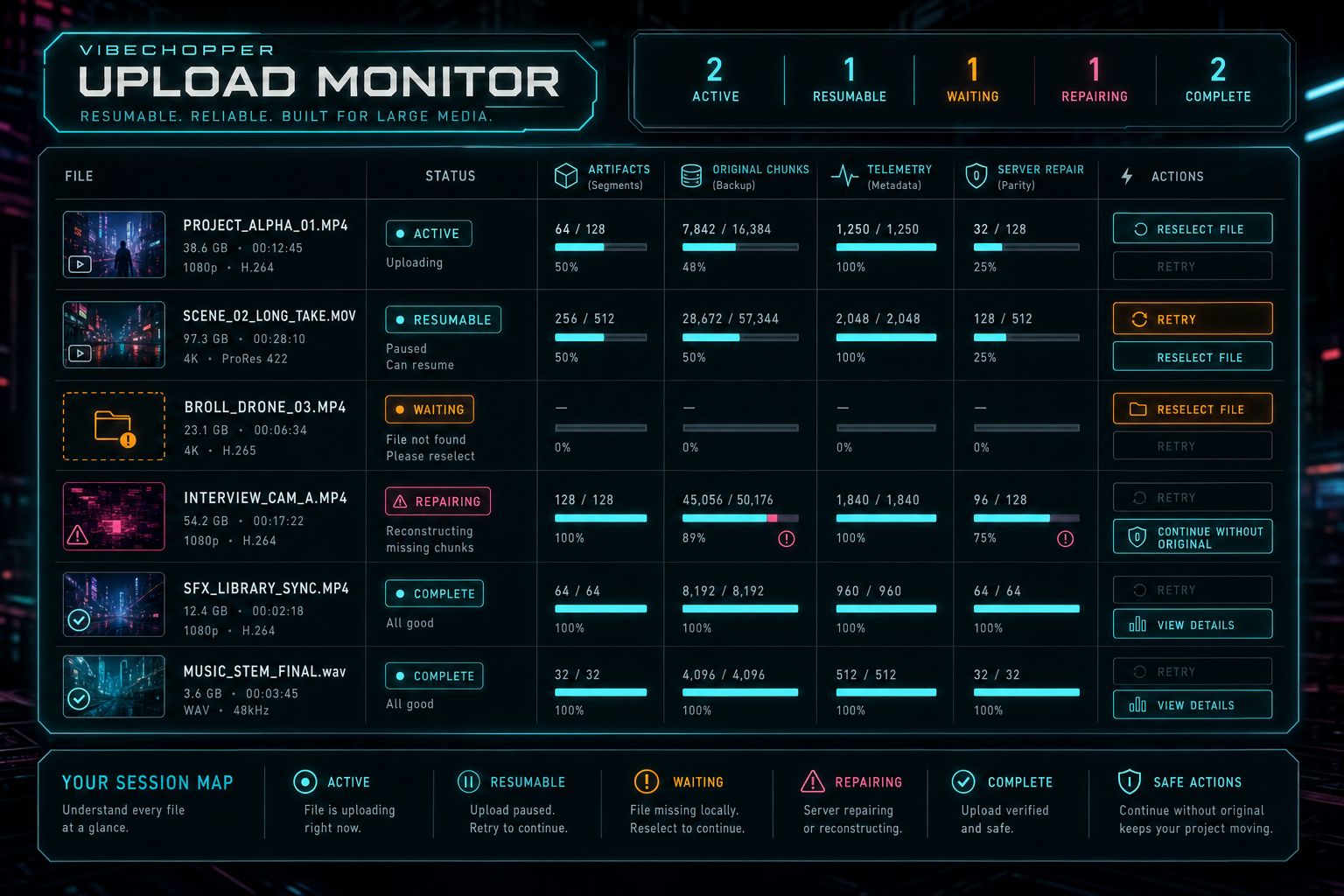
The session state is the user's map: which files are moving, blocked, complete, repairable, or waiting for local reselect.
Browser Resume Storage Has to Be Honest
Browser resume is not the same as server resume. Server resume can remember chunk receipts and committed media. Browser resume depends on what the browser is still allowed to read. A serious architecture treats that as a first-class constraint.
The local layer should store a manifest for each selected file: project ID, upload session ID, local file ID, file name, file size, MIME type, last modified time, content hash progress, chunk size, uploaded chunk indexes, artifact references, and whether a file handle is available. It can also store derived artifacts such as thumbnails, compressed frame samples, audio snippets, transcript drafts, or metadata packets in IndexedDB or OPFS. Those artifacts can reduce repeated work after refresh even when the original file must be reselected.
File handles are useful when the platform supports them, but they are not a universal answer. The app should check permission before reading. It should ask for persistent storage when appropriate. It should surface quota limits and capability gaps as recoverable product states. When the browser cannot reopen the local file automatically, the UI should say exactly that and ask the user to reselect the file. That is more credible than silently failing a background retry.
The key design move is to separate source access from derived work. If the browser has already generated frame artifacts or metadata, those should not be thrown away just because the original source handle needs reauthorization. If the server already has the original source, the browser should not redo local extraction solely because a UI component remounted. Recovery should preserve every durable milestone the system can trust.
This is especially important for large media projects because creators often upload in batches. One file may be fully committed, another may be waiting for a local reselect, another may be running server repair, and another may be ready for AI analysis. A local resume store and a server session model have to merge those states into one clear monitor.
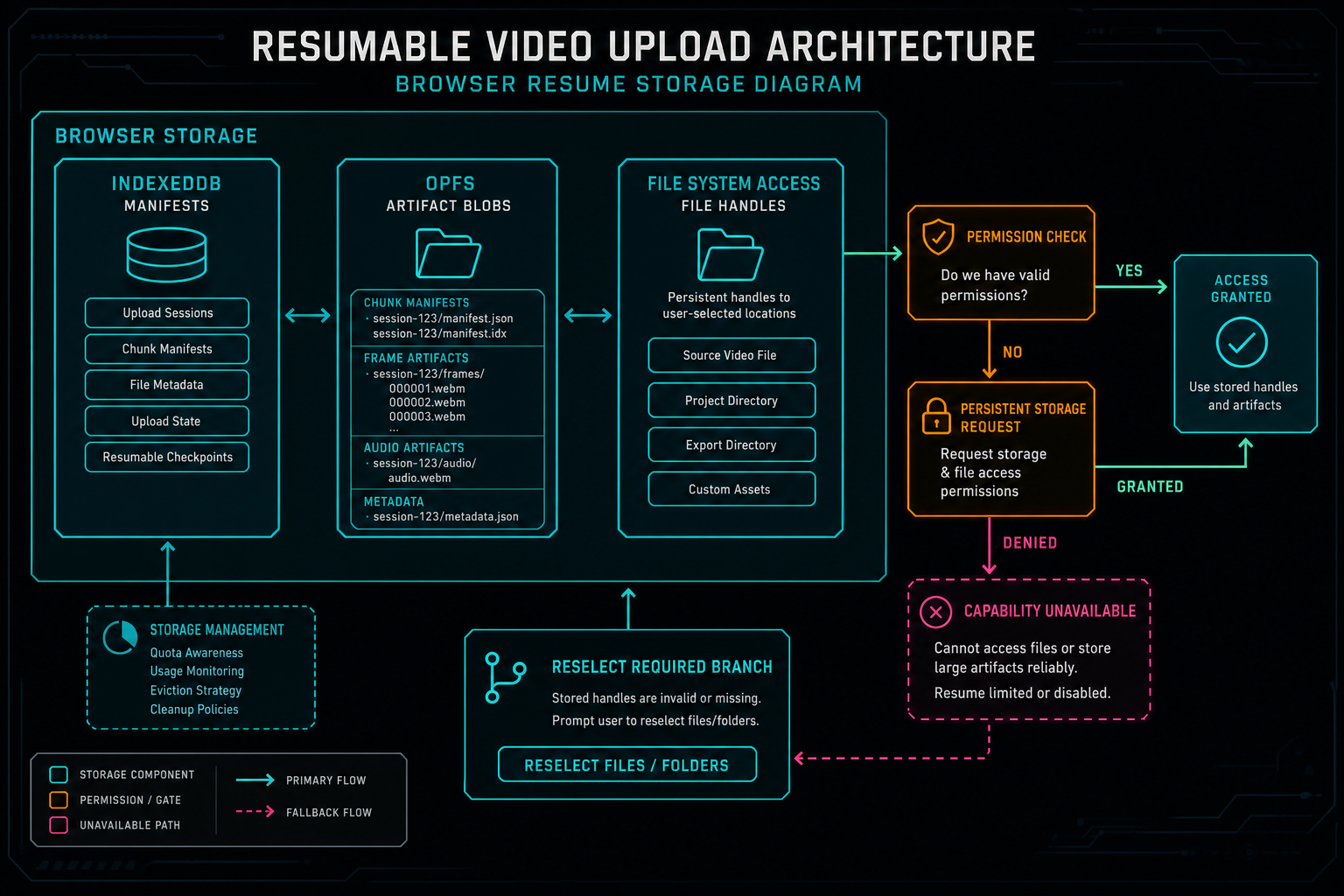
Resume support begins in the browser, but it must respect storage quotas, file permissions, and platform capabilities.
Make the Chunk Protocol Idempotent
Chunking is the mechanical core of resumable upload, but the protocol has to be shaped by product constraints. Each chunk request should be authenticated, scoped to an upload session, tied to a file identity, and safe to retry. If the same chunk arrives twice after a network timeout, the server should recognize the duplicate and return success when the stored receipt matches. A retry should not corrupt the final object.
A practical chunk record includes upload session ID, session file ID, chunk index, byte start, byte end, chunk size, chunk checksum, receipt time, and storage reference. The server can accept chunks in order or out of order depending on the storage strategy, but final commit should verify the manifest. The declared file size, chunk count, uploaded chunk receipts, and final checksum need to agree before the source file becomes canonical media.
The commit step should also be idempotent. A client that times out while committing should be able to ask again without creating two originals or two video records. The server can return the already committed media record when the manifest and ownership match. This is the difference between a retryable protocol and a protocol that only works while every request returns perfectly.
Where chunks live before commit depends on infrastructure. Some systems use multipart upload directly into object storage. Others receive chunks through the app server and write temporary parts. Either way, the final promotion should happen on the server side because it is the server that can verify user ownership, project membership, object path policy, quota, media record creation, and downstream processing triggers.
The chunk protocol should not leak into the rest of the editor. The timeline does not need to know which chunk finished last. It needs a source video record with durable storage, file metadata, processing state, and provenance. Keep chunk mechanics behind the upload service and promote only verified media into editor-facing models.
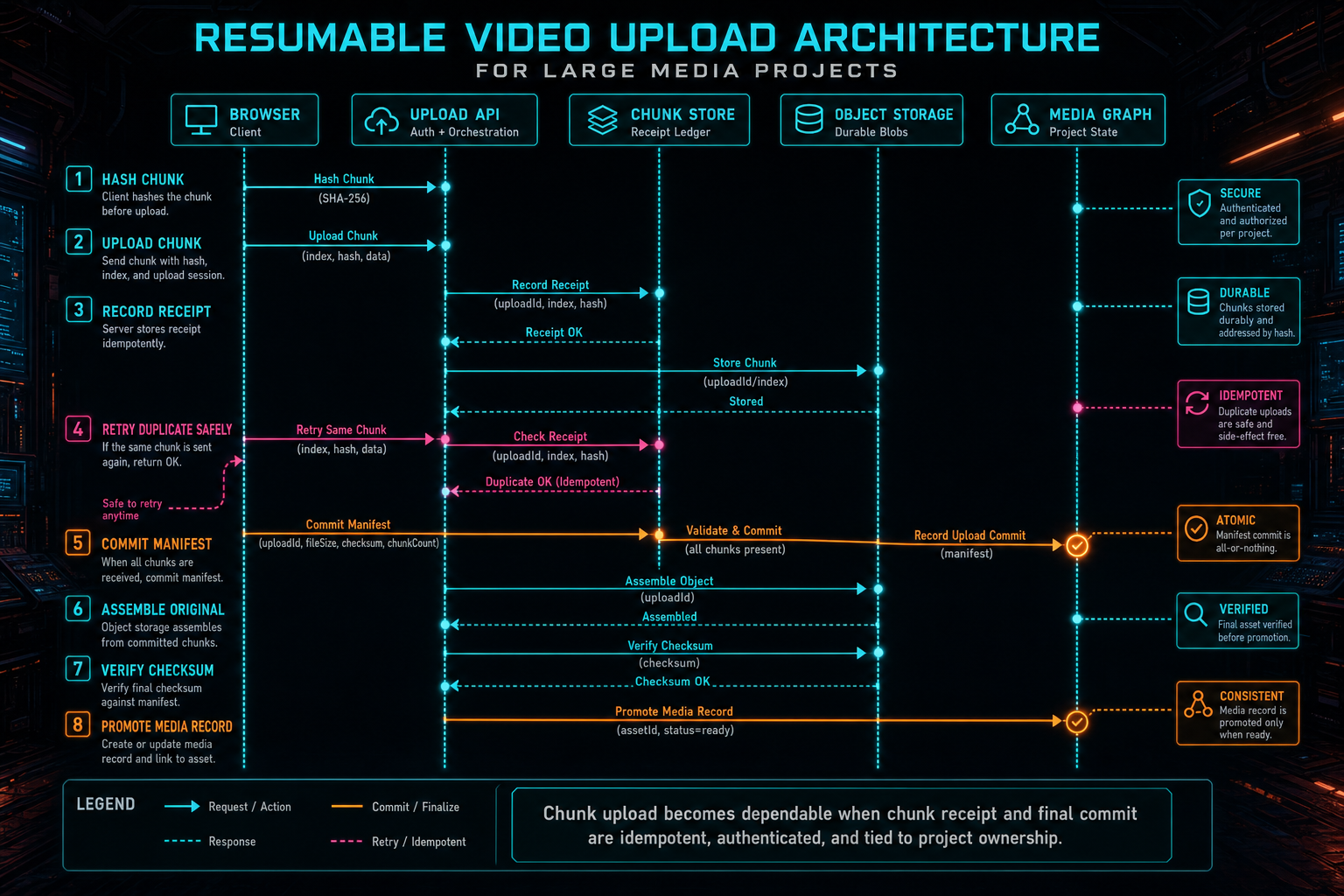
Chunk upload becomes dependable when chunk receipt and final commit are idempotent, authenticated, and tied to project ownership.
Telemetry Turns Upload Into an Observable Workflow
Progress bars are easy when everything is fast. They get hard when a large file takes long enough for bandwidth, CPU, browser throttling, and retries to matter. A resumable upload architecture needs telemetry not for vanity dashboards, but to make the product honest. Send feedback with context
Useful upload telemetry includes transferred bytes, total bytes, bytes per second, elapsed time, predicted ETA, active stage, current chunk, retry count, stalled duration, connection type, device context, browser context, and request context. For a media project, it is also useful to distinguish original upload ETA from artifact readiness. A user may be able to start editing with frames and transcript before the full original upload has finished.
Telemetry should feed decisions. If throughput drops to zero but the session heartbeat is active, the monitor can show a stalled original chunk rather than a generic failure. If the browser no longer has source permission, the monitor can show a reselect-file action. If server repair is active, the UI can stop blaming the browser and show that backend processing is filling the gap. If a user reports a problem, the support packet can include structured stages and samples rather than a screenshot of a frozen bar.
ETA should be presented as a useful estimate, not a guarantee. Network speeds swing. Browser tabs get backgrounded. Object storage can have temporary latency. The right promise is not perfect prediction; it is explainable movement. Show the active stage, show whether bytes are still moving, show what is waiting, and keep completed milestones visible.
This is where upload architecture overlaps with broader observability. The same discipline that makes render jobs and AI edit runs inspectable also applies to upload. Long-running creative workflows need state, not mystery. When the product can name the stage, it can guide the user and give developers a specific place to investigate.
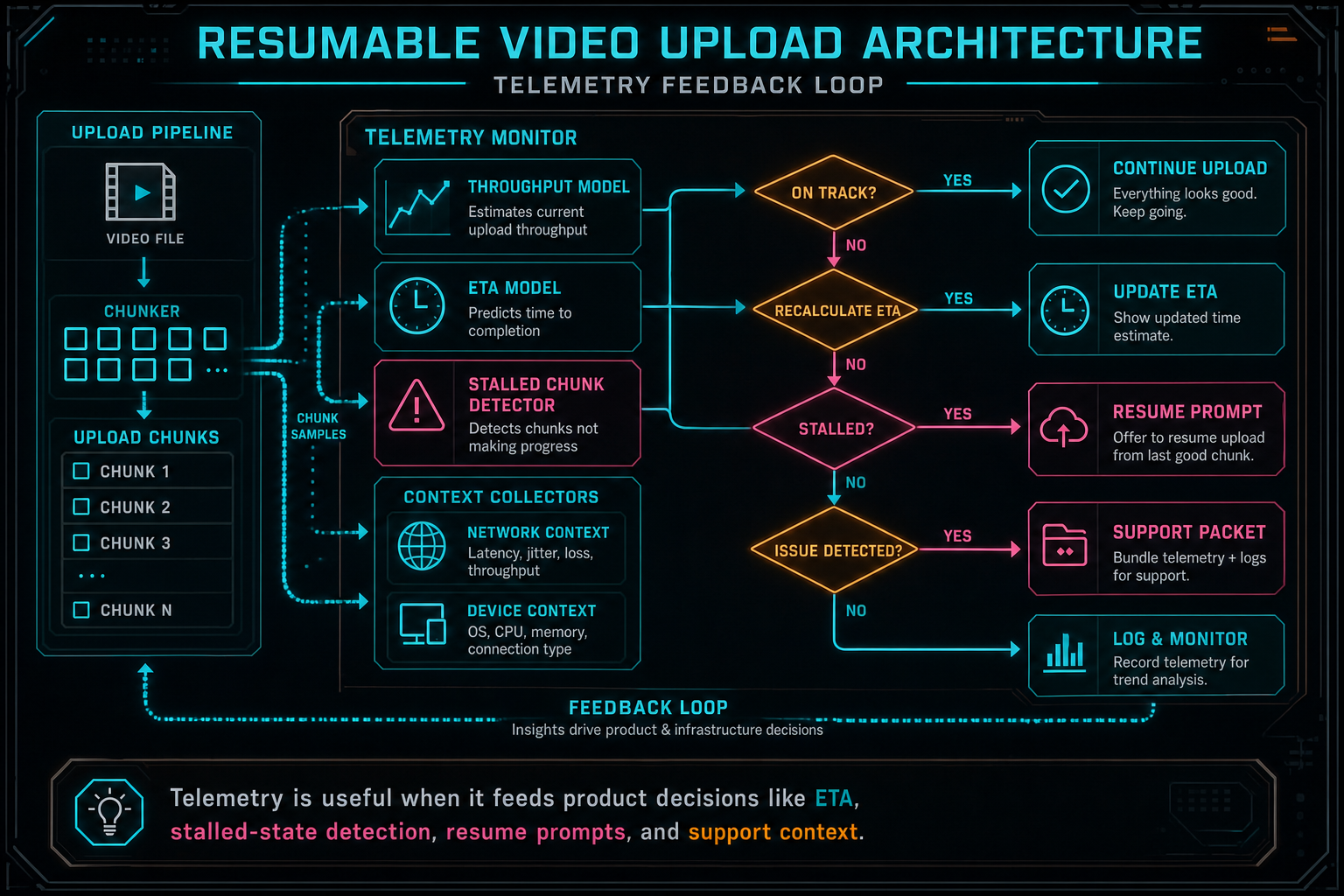
Telemetry is useful when it feeds product decisions like ETA, stalled-state detection, resume prompts, and support context.
Server Repair Is Part of Resumability
Many upload systems define resumability as can the remaining bytes be sent later? A video editor needs a wider definition. The project is resumable when the system can continue building usable media state after interruption. That includes source bytes, but it also includes frames, audio, transcript, metadata, thumbnails, proxies, and repair jobs. Explore your media graph
Browser processing is valuable because it can make the editor feel immediate. The client can extract representative frames, prepare audio, and start showing progress before a server job finishes. But browser processing is not equally reliable across devices, codecs, memory conditions, and permissions. A product-grade upload path should be able to fall back to server-side extraction when the original file is available.
That means original upload has strategic value beyond backup. Once the server has a trusted source file, it can repair missing derived media. If local frame extraction fails, server extraction can create the frame set. If audio upload is interrupted, server audio extraction can recover it. If transcript work fails transiently, the stored source or audio artifact can be retried. The upload monitor should show those repair lanes as normal workflow, not as hidden background magic.
The media graph is what keeps this coherent. Each derived artifact should know which source it came from and which processing path created it. A transcript generated after server repair should still connect to the same project media. A proxy created later should not look like an unrelated upload. Provenance lets repair strengthen the project instead of creating duplicate mystery assets.
In this architecture, resumable upload and media processing are not separate features. Upload provides the durable source and the session state. Processing creates the editor context. Repair reconnects missing pieces. The user sees a single product surface: this file is active, this part is waiting, this part is repaired, and this part is ready to edit.
Security and Ownership Are Core Requirements
Large media uploads carry sensitive creative work. A resumable upload API has to enforce ownership on every step, not just at final commit. Chunk upload, chunk status, session heartbeat, session file update, telemetry write, commit, repair trigger, and media record promotion should all authenticate the user and verify project scope.
Do not let the client choose arbitrary object storage paths. Do not let one user's upload ID reveal whether another user's chunks exist. Do not accept commit manifests that reference chunks outside the authenticated session. Do not promote a source object into a project until the server has verified ownership and manifest integrity. These are basic rules, but resumable protocols create many small endpoints where shortcuts can sneak in.
Retention rules matter too. Temporary chunk parts should expire. Abandoned sessions should be marked stale or ended. Telemetry should be useful without retaining unnecessary sensitive detail forever. If a user deletes a project, media records, original objects, derived artifacts, temporary parts, and upload session remnants should follow the product's data lifecycle policy.
The same ownership discipline benefits product behavior. When every upload row is user-scoped and project-scoped, the editor can safely hydrate progress after refresh. The media panel can show only the current user's assets. Render jobs can resolve sources through trusted storage references. AI edit runs can cite artifacts without copying raw URLs through untrusted channels.
What Developers Should Copy
If you are building resumable upload for a video product, start with the state model before choosing the chunk library. Define upload sessions, session files, stage vocabulary, heartbeat semantics, duplicate handling, commit rules, and retention. The transport implementation will be much easier to reason about once the product state is explicit. Upload a real shoot
Separate local resume from server resume. Local resume is about browser capabilities, stored manifests, file handles, IndexedDB or OPFS artifacts, and reselect-file recovery. Server resume is about authenticated sessions, chunk receipts, idempotent commits, object storage, and media record promotion. Both are necessary, but they fail differently and should be explained differently.
Track artifact readiness separately from original byte progress. In a video editor, frames, audio, transcript, and metadata are not decorative side effects. They are the inputs that make search, AI edits, rough cuts, captions, review, and render verification possible. Show users what is ready, not only what percentage of a source file has crossed the wire.
Make every retry safe. Chunk upload should tolerate duplicate chunks. Session updates should be upserts. Commit should return the existing canonical media record when the same manifest is already complete. Processing triggers should avoid launching duplicate repair jobs for the same missing artifact. Resumability without idempotency is only partial reliability.
Finally, test the state machine outside the UI. Feed representative states into a plain model: active upload, stalled chunk, completed artifacts with pending original, lost file permission, stale session, duplicate commit, server repair active, object storage failure, and completed media promotion. Assert filters, actions, percentages, ETA fields, and user-safe messages. The upload dialog can be polished later; the state machine has to be true first.
The Result
The finished behavior is simple for the creator. Select large source clips. VibeChopper starts a user-scoped upload session, tracks each file independently, streams resumable progress, preserves local artifacts where the browser allows it, commits original bytes into durable object storage, repairs missing derived media on the server, and promotes verified media into the project graph. If the tab refreshes or the network drops, the monitor shows what can continue automatically and what needs the user's help. Upload a real shoot
The engineering underneath is a set of deliberate contracts: browser resume storage, upload sessions, per-file state, chunk receipts, idempotent commit, object storage policy, telemetry samples, repair lanes, media provenance, and safe UI actions. None of those pieces should be hidden inside one generic upload promise. Large media projects deserve state that survives the real world.
That architecture pays off beyond upload. AI editing depends on frames, transcripts, and source provenance. Cloud rendering depends on trusted original media and durable storage paths. Feedback and remediation depend on structured state. Collaboration depends on project-owned media records. A resumable video upload pipeline is not only about finishing bytes; it is about giving the whole editor a reliable media foundation.
The public experience can still feel direct: upload footage, watch progress, and start editing with voice and timeline precision. The reason it feels direct is that the architecture underneath refuses to pretend large media is simple. It names the moving parts, makes them recoverable, and turns interruption into a state the product can handle.

The upload is finished when the editor has durable media context, not only when the last byte reaches storage.
Try the workflow
Open every feature from this post in the editor
These panels collect the features discussed above. Sign in once, finish your profile if needed, then the editor opens the first highlighted surface and walks through the tutorial.
Step 1
Upload footage with progress you can trust
Watch large video uploads, processing, transcript work, and original-file storage from one monitor.
Upload a real shoot →Step 2
Open the media asset graph
See generated audio, rendered assets, source clips, metadata, and provenance in the media panel.
Explore your media graph →Step 3
Send contextual feedback
Capture voice or written feedback with project context so issues can become repairable jobs.
Send feedback with context →Step 4
Try voice-driven timeline edits
Describe the edit you want and let VibeChopper translate intent into timeline changes.
Talk a cut into shape →Step 5
Render a verified timeline
Export a project through the same storage-backed render path described in this article.
Render a timeline free →