Why a Harness Exists
A natural-language video editor has a different relationship with AI than a chat box does. A chat box can tolerate a little drift. A timeline cannot. If a user says, "trim the dead air before the second speaker starts," VibeChopper has to turn that intent into bounded operations against clips, transcript spans, renderable media, and undoable project state. The model can help reason about the request, but the product still needs deterministic contracts. Talk a cut into shape
That is the reason for a provider-agnostic completion harness. The harness is the narrow waist between product intent and model-specific APIs. Editor features ask for a completion through one internal shape. Provider adapters translate that shape into the details required by each upstream model. The response comes back through validation, retry policy, fallback handling, and usage logging before any downstream edit flow trusts it.
The audit trail for this work points to server/providers/harness.ts and commit 30331fd, where the provider harness became a platform concern instead of a one-off call site. The same audit also names the larger 2026-05-17 to 2026-05-18 platform hardening wave: AI edit runs, tool events, render verification, compositor effects, upload telemetry, owned auth, passkeys, and themed platform emails. The harness is one piece of that wave, but it explains a lot about how VibeChopper thinks: AI is useful when it is wired into accountable product systems.
If you want to feel the user-facing side of that architecture, the quickest path is to try a voice-driven edit in the editor. The button nearby takes you through login and lands you in the editor with the voice-edit intent. Under the surface, that simple flow depends on the same contract discipline described here.
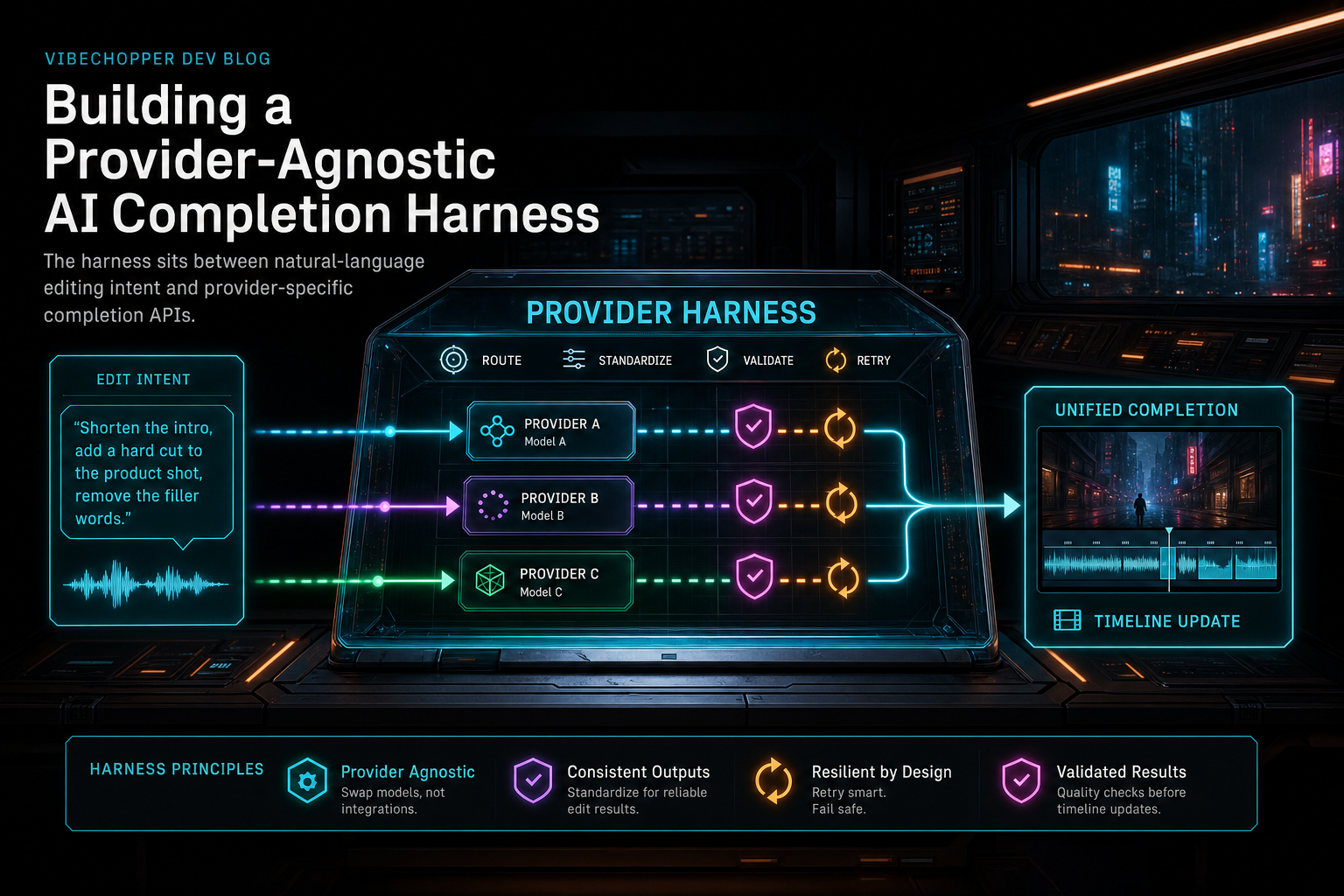
The harness sits between natural-language editing intent and provider-specific completion APIs.
The Product Contract Comes First
Provider independence does not start by writing three adapters. It starts by refusing to let provider details define the product contract. VibeChopper needs to ask questions like: what is the user trying to do, what project context is available, what output shape can the caller safely consume, and how should failure be reported? Those questions are stable even when models, SDKs, endpoint names, pricing, and token accounting change.
A completion request in this style carries normalized intent, messages or instructions, model preferences, response format expectations, and operational metadata. It can include the kind of job being performed, such as edit planning, command extraction, transcript interpretation, or rubric scoring. It can also carry enough context for logs to connect the completion back to a project, a user action, or an AI edit run without asking every caller to reinvent observability.
The adapter layer is intentionally less glamorous. It maps the internal request into provider-specific fields, invokes the upstream service, and returns a normalized result. The harness owns the policy. The adapter owns translation. That separation matters because policy is a product decision. Translation is a vendor integration detail.
This is also how you avoid letting a model migration become a product rewrite. If an editor command parser knows about one provider's SDK response object, then every future provider decision leaks into product code. If the command parser knows only about a validated VibeChopper completion result, then provider changes stay contained. You still test migrations seriously, but you do not have to rewire the editor every time the AI market moves.
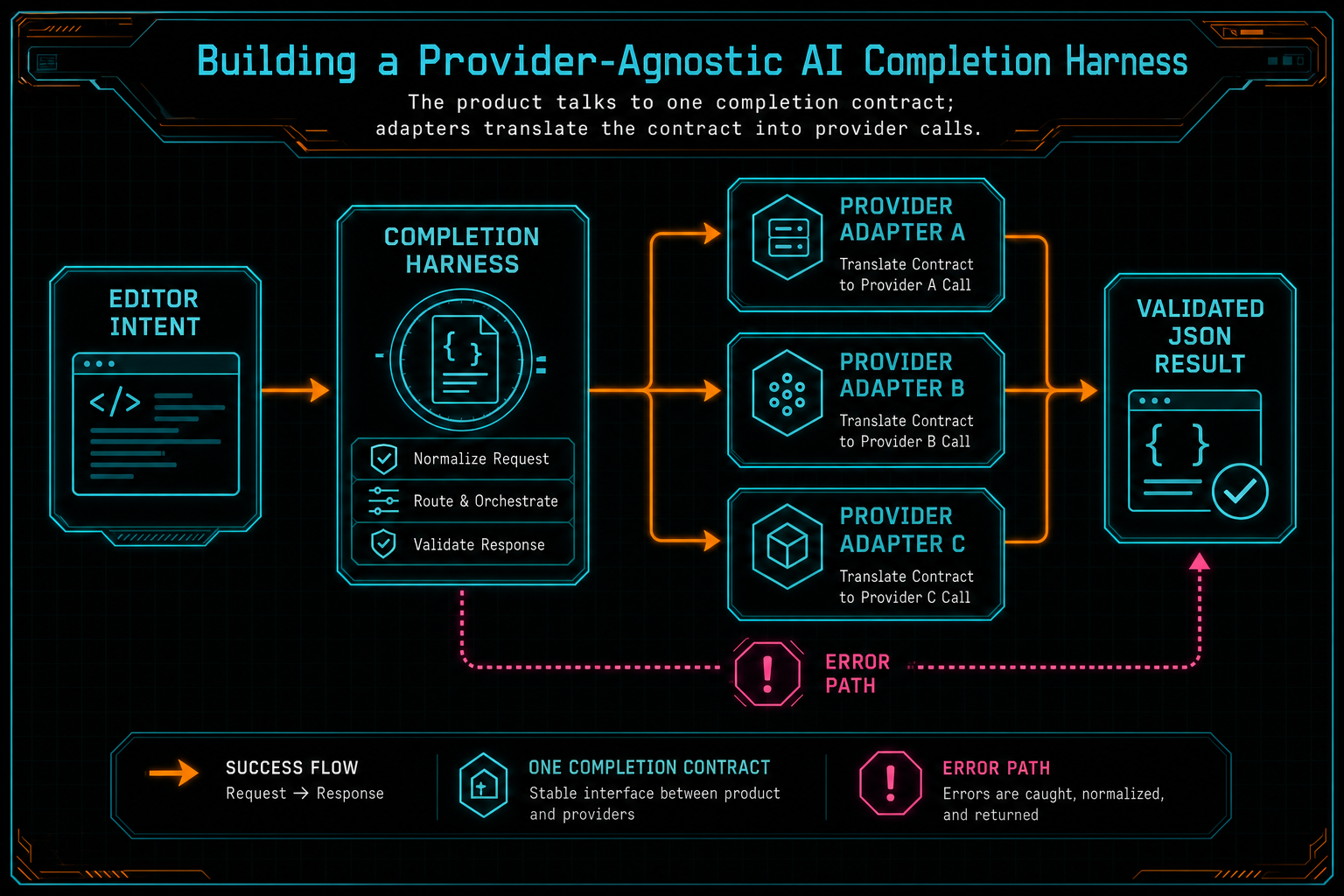
The product talks to one completion contract; adapters translate the contract into provider calls.
Structured Output Is a Boundary
The most important sentence in this article is boring: never send unvalidated model output into editing tools. In VibeChopper, AI suggestions become useful only after they pass through a typed boundary. For JSON completions, the harness treats structure as part of the contract, not as a hint. A provider can return text that looks correct and still be wrong in ways that matter: missing fields, ambiguous enum values, impossible time ranges, invalid media references, or a confident command that points at a clip the user does not own. Open the edit-run receipts
The audit notes call out JSON validation as a core angle of the provider harness. That validation is what lets later systems be stricter. AI edit runs can record planned tool calls. Tool event streams can show what changed. Render verification can check whether output artifacts are attached to the right timeline. None of those systems should have to guess whether a completion had the shape it promised.
Validation also improves the prompt loop. A rejected response is not just a failure. It is information. The harness can retry with a repair instruction, fall back to another provider, or return a clear error to the caller. The caller can decide whether to ask the user for more context or preserve the current timeline unchanged. That is how the editor stays calm when the model has a messy moment.
For developers evaluating VibeChopper from the outside, the AI edit run view is the most direct way to see this philosophy. It connects plans, tool calls, artifacts, and render results instead of treating a completion as a magic string. The inline CTA here opens that path.
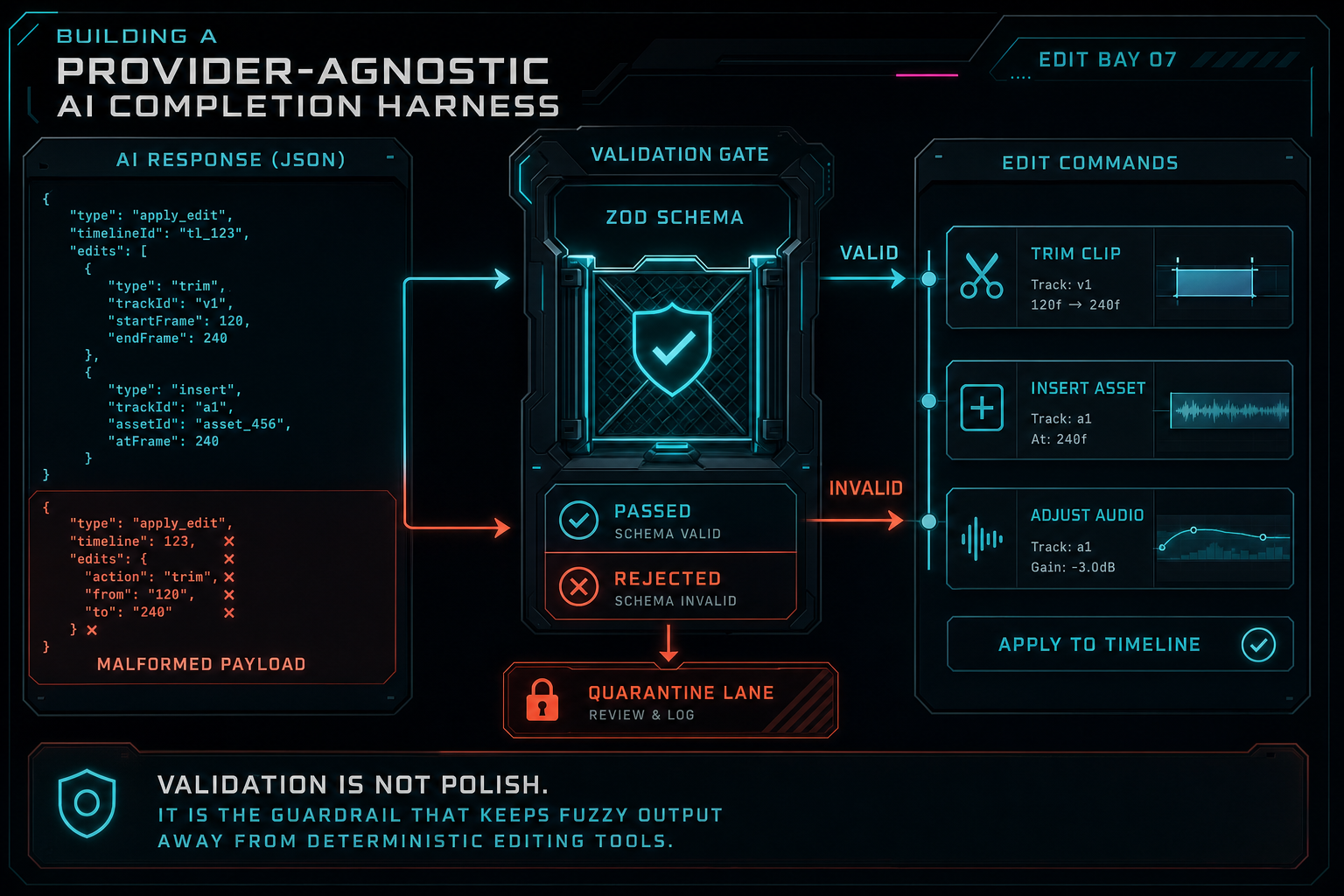
Validation is not polish. It is the guardrail that keeps fuzzy output away from deterministic editing tools.
Retries Are Not Fallbacks
A retry and a fallback solve different problems. A retry says the same provider may succeed if the transient condition clears: a timeout, a rate-limit window, a temporary transport failure, or a malformed response that can be repaired. A fallback says the product should attempt a different provider because the primary route cannot satisfy the request right now.
Blending those ideas into one vague "try again" loop creates bad behavior. You can waste time hammering a rate-limited endpoint. You can accidentally double-spend on expensive requests. You can return different semantic answers across retries without recording why. In video editing, you can also leave a user staring at a spinner while the editor knows enough to choose another route.
The provider harness gives the product a place to encode retry caps, timeout behavior, provider ordering, response repair policy, and error classification. That policy should be boring, explicit, and logged. It should answer simple operational questions: how many attempts happened, which provider answered, which model was used, how long did it take, did validation pass on the first try, and what error category ended the run if it failed?
Fallback is not only about uptime. It is also about preserving product independence. VibeChopper can choose the best provider for a task, then change that choice later as capabilities shift. Some models may be stronger at structured planning. Some may be better at caption-aware reasoning. Some may be reserved for fast UI assistance. The harness lets those choices evolve behind one completion API.
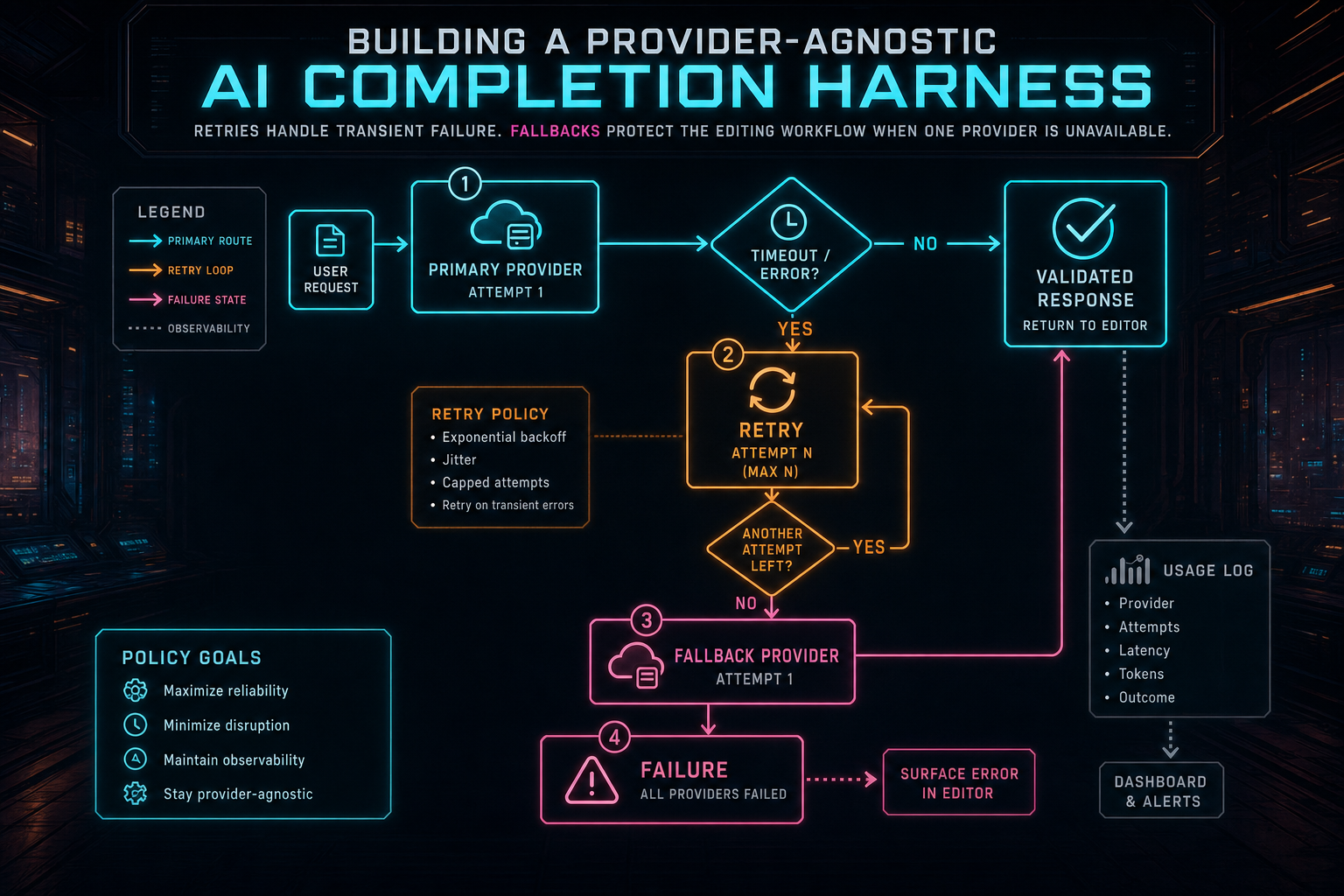
Retries handle transient failure. Fallbacks protect the editing workflow when one provider is unavailable.
Usage Logs Are Product Infrastructure
Usage logging sounds like finance plumbing until you build an AI creative tool. Then it becomes product infrastructure. A completion record can answer cost questions, but it also answers trust questions. What provider generated this plan? Which model interpreted the transcript? Was the output validated? Did the result feed an edit run, a music artifact, a render verification step, or a remediation job? Explore your media graph
The developer audit names usage logs as part of the harness angle, and it names nearby systems that make those logs more valuable: media processing summaries, AI edit runs, generated music provenance, render verification, and DATA remediation status. The pattern is consistent. Generated or AI-assisted work should leave enough context for the system to explain, repair, or reproduce the important parts of the workflow.
A provider-agnostic harness helps because it can normalize usage fields before they disappear into provider-specific dashboards. Tokens, latency, request IDs, provider names, model identifiers, validation state, fallback state, and calling feature all belong near the completion boundary. You do not want every feature team hand-rolling that telemetry.
The same idea shows up in the media panel. Source clips, generated audio, rendered assets, metadata, and provenance become more useful when they are connected. If you are exploring VibeChopper as an editor, open the media asset graph and look for that connective tissue. The public product promise is simple: edit by vibe, voice, and timeline context. The backend promise is that context does not vanish after one model call.
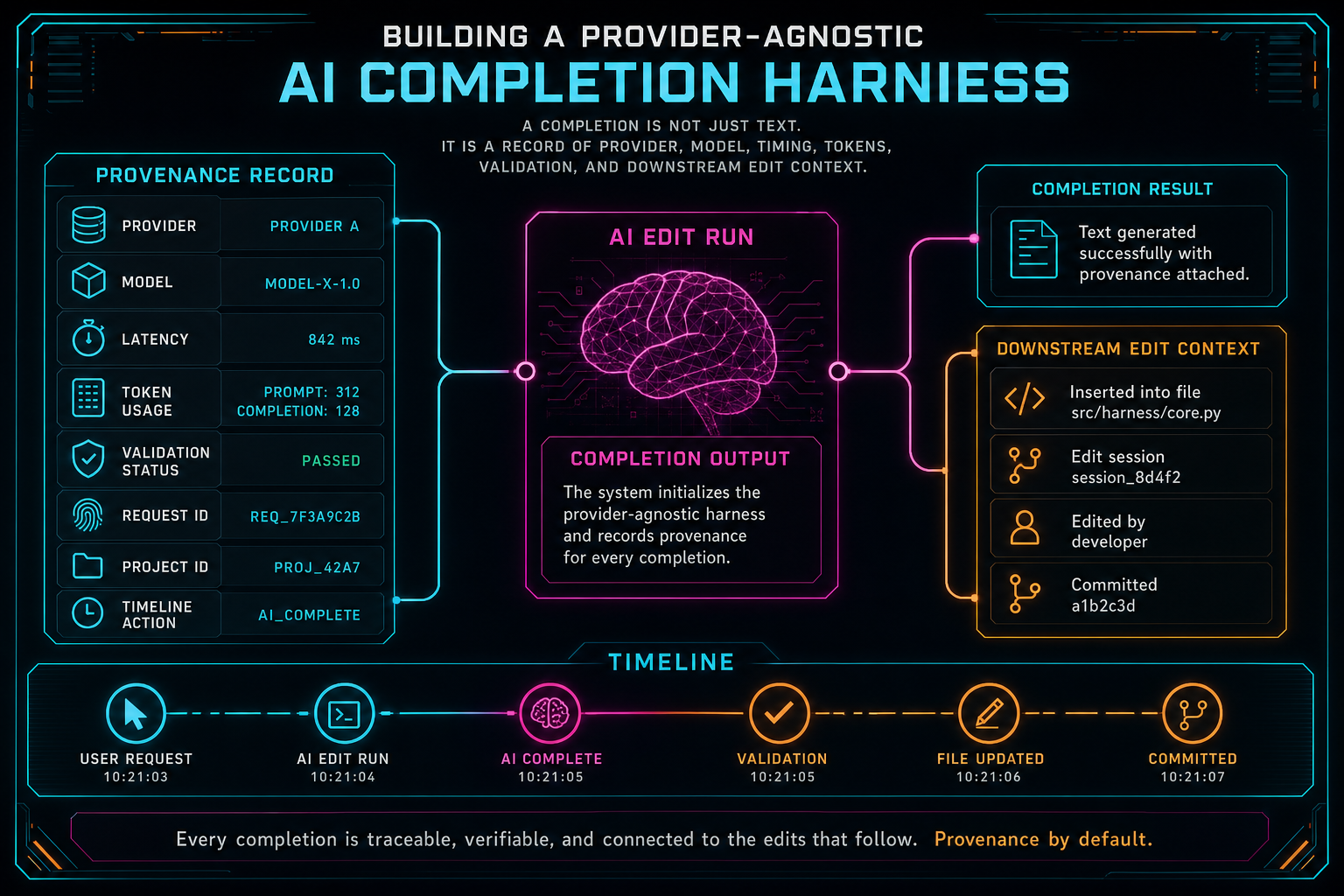
A completion is not just text. It is a record of provider, model, timing, tokens, validation, and downstream edit context.
Video Editing Context Changes the Prompt
Generic completion wrappers often stop at messages, temperature, and max tokens. That is not enough for a video editor. VibeChopper has clips, frame descriptions, transcript spans, speaker labels, timeline selections, project ownership, render artifacts, upload state, and undoable edit history. The prompt surface needs to carry enough context for useful reasoning while the server still protects private data and validates every action.
This is where provider agnosticism gets practical. The caller should not have to know how one provider prefers system instructions or how another provider handles JSON mode. The caller should describe the editing job and the available context. The harness should convert that into a provider request without changing the caller's mental model.
That separation also helps with test design. You can test the editor command parser against normalized completion results. You can test provider adapters with mocked upstream responses. You can test validation failure without hitting a live model. You can test fallback order as policy. The point is not to pretend AI is deterministic. The point is to make the non-deterministic part small enough to surround with deterministic checks.
The audit connects this harness to the broader AI edit harness and platform hardening wave. That connection is important. Natural-language editing is not a single prompt. It is request interpretation, plan formation, tool execution, artifact tracking, render verification, and user-visible recovery when something fails. A provider harness gives that chain a stable first link.
What We Avoid
We avoid provider-shaped product code. It is tempting when moving fast. A provider SDK returns a convenient object, a demo works, and suddenly business logic depends on a response shape the product does not own. That shortcut gets expensive as soon as a second provider enters the stack or a structured-output behavior changes.
We avoid treating model text as authority. The model can propose. The server decides. For a video editor, the server owns authorization, project lookup, media references, timeline bounds, object storage paths, and persistence. A completion that asks to edit a project still has to pass the same ownership and validation rules as any other route.
We avoid hiding errors that creators can act on. If a request fails because the transcript is missing, the editor can ask for upload or processing. If a provider fails, the harness can fall back or report a service issue. If validation fails repeatedly, the product can preserve the current state and ask for a clearer instruction. The user should not have to debug a provider outage by watching their timeline do nothing.
We also avoid pretending all AI calls are the same. A low-latency UI suggestion, a structured edit plan, a second-pass review rubric, and a remediation summary have different risk profiles. They deserve different model choices, retry policies, and validation schemas. One harness can support those differences because it centralizes policy without flattening the product into one generic prompt pipe.
The Result
A provider-agnostic completion harness is not glamorous infrastructure. It is the kind of layer users notice only because the editor feels steadier. Voice edits can be routed through the right model. Structured plans can be validated before tools run. Usage can be recorded without every feature inventing its own log shape. Fallbacks can keep the workflow moving when one provider is having a rough day.
For VibeChopper, that matters because the product promise is direct: describe your edits, and the editor understands your intent and executes precise edits. Behind that sentence is a stack that has to respect both creativity and state. Providers can change. Models can improve. Pricing can move. The timeline still needs a trustworthy contract.
That is the harness job. Keep the model layer powerful, but keep the product in charge. Let AI reason about the vibe, then make the server prove the shape, record the path, and hand deterministic work to deterministic systems. That is how natural-language editing becomes more than a demo. It becomes a workflow creators can come back to.
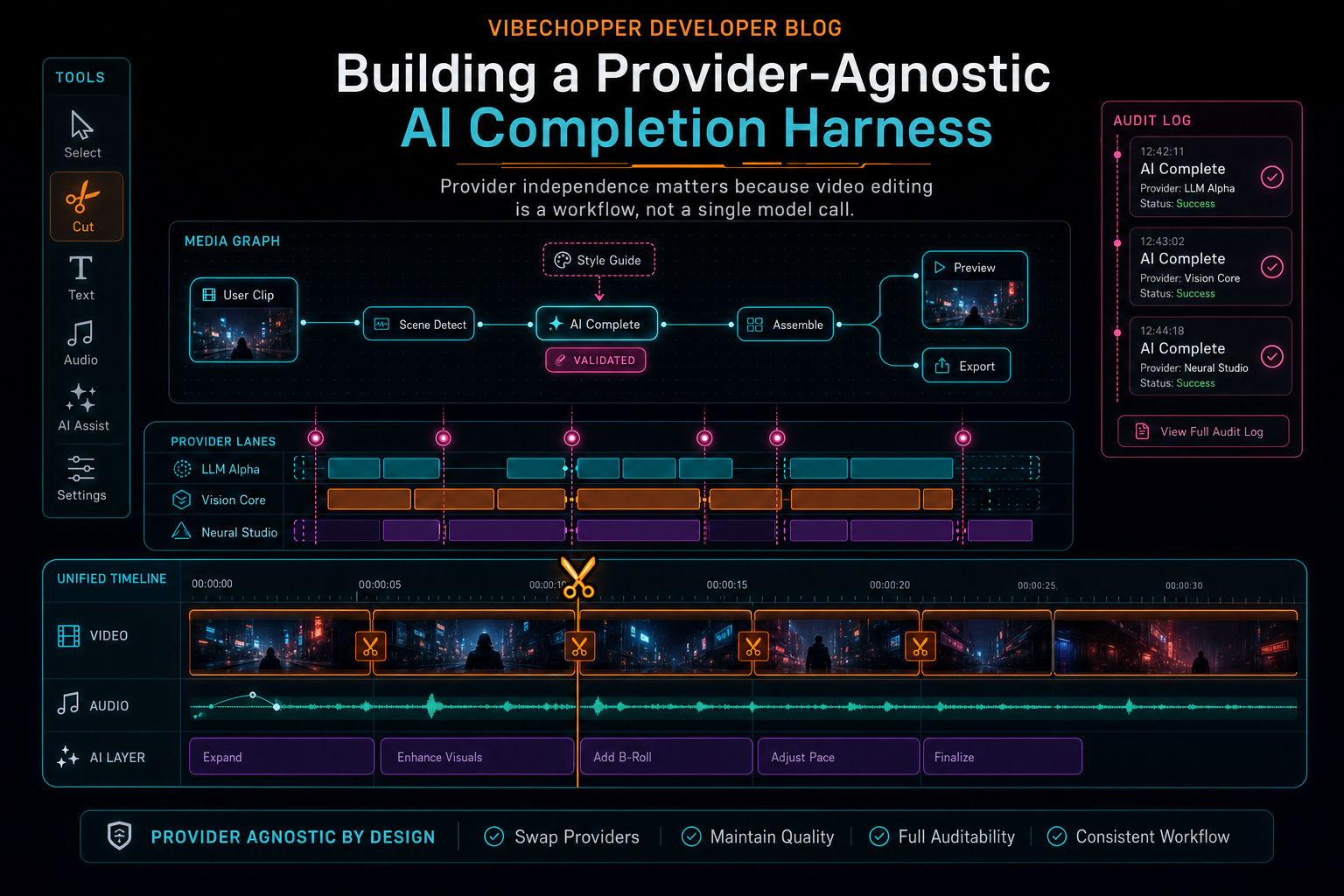
Provider independence matters because video editing is a workflow, not a single model call.
Try the workflow
Open every feature from this post in the editor
These panels collect the features discussed above. Sign in once, finish your profile if needed, then the editor opens the first highlighted surface and walks through the tutorial.
Step 1
Try voice-driven timeline edits
Describe the edit you want and let VibeChopper translate intent into timeline changes.
Talk a cut into shape →Step 2
Inspect an AI edit run
Open the editor and see how plans, tool calls, artifacts, and render results stay connected.
Open the edit-run receipts →Step 3
Open the media asset graph
See generated audio, rendered assets, source clips, metadata, and provenance in the media panel.
Explore your media graph →