Why Headless Work Needs a Tracker
The first version of any repair loop is usually simple: receive feedback, ask an engineer or agent to look at it, and hope the fix ships. That can work inside a small team, but it does not work as a product surface. Users do not experience a background repair as progress unless the system shows them what is happening. They experience silence. Send feedback with context
DATA Remediation is VibeChopper's answer to that gap. A user can report feedback with editor context, and the platform turns that report into a durable remediation job. The job can be claimed by a worker, acted on by a headless agent, checked, published, verified, and connected back to a public status page. The worker is allowed to run away from the request path, but the work itself stays visible.
That distinction matters. Headless remediation is useful because production repairs do not fit cleanly inside a single HTTP request. A repair may need repository context, scoped file changes, focused tests, TypeScript checks, AI verification, a commit, a push, a publish adapter, and a production URL check. A user should not have to wait on that request. The platform should accept the report, create the job, and let asynchronous workers carry the repair forward.
But asynchronous does not mean invisible. In VibeChopper, the worker reports signed lifecycle events. The public tracker reads server-owned job state and recent events. A submitter can refresh the status page and see whether the job was received, planned, built, checked, published, or verified live. That is the product promise: not magic repair, but trackable repair.
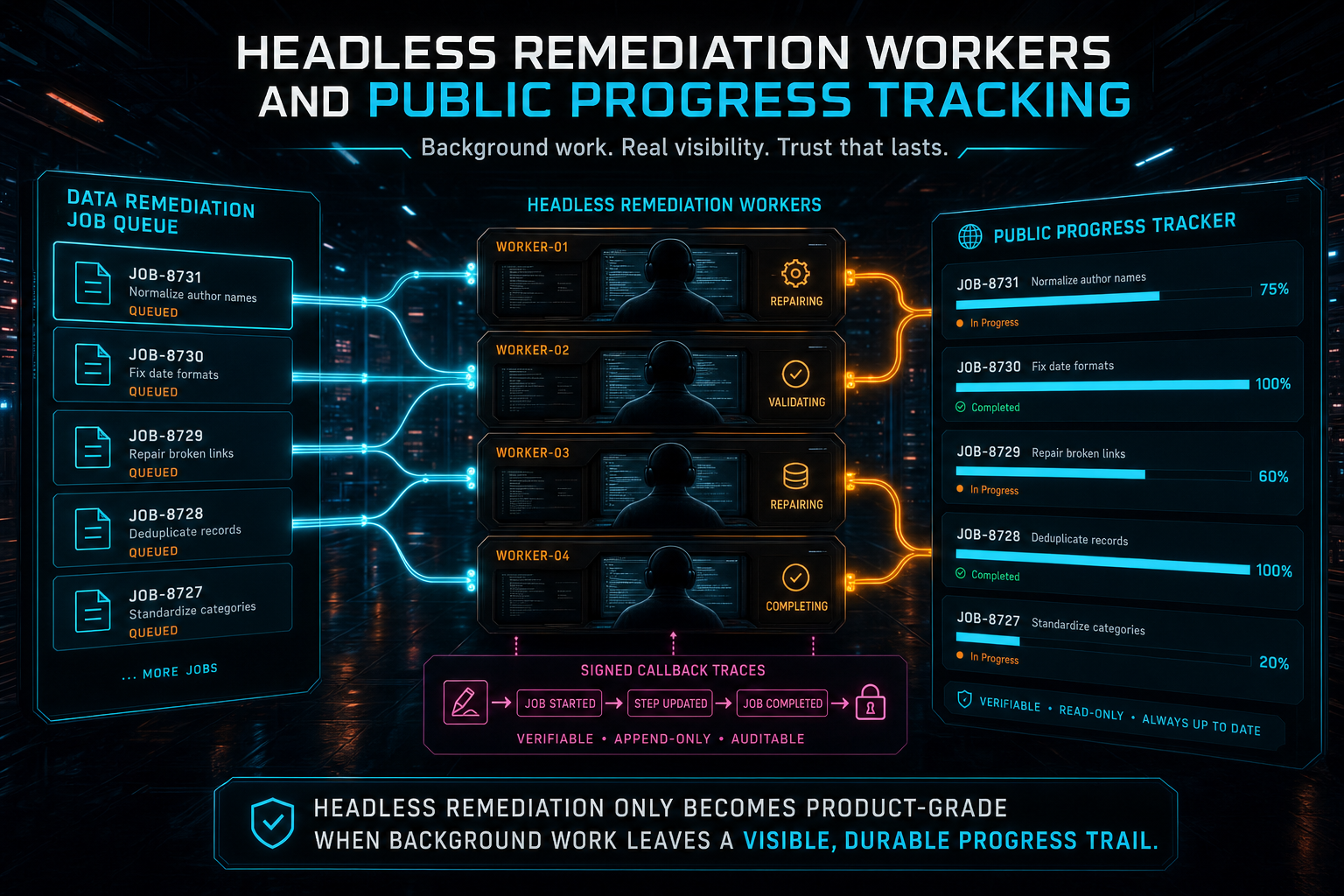
Headless remediation only becomes product-grade when background work leaves a visible, durable progress trail.
The Worker Contract
The worker contract lives in scripts/data-remediation-worker.ts. The script reads a server URL, worker ID, shared secret, SSH command, production URL, once flag, and poll interval from CLI flags or environment variables. It requires the server URL, the worker shared secret, and the SSH command because a headless worker without a callback endpoint or dispatch path cannot safely move a job. Open the edit-run receipts
The first action is claim. The worker posts to /api/data-remediation/worker/claim with a worker ID and a capability list that includes ssh-dev-runner, headless-agent, codex, claude, checks, main-push, and publish-adapter. That capability list is not decorative. It tells the queue what kind of work this worker is prepared to perform and gives operators a concise way to understand the automation surface.
If no job is available, the worker logs that no DATA Remediation job was claimed. If a job is available, the worker emits ssh_dispatch_started, then launches the dev runner over the configured SSH command. The remote command sets DATA_REMEDIATION_SERVER_URL, DATA_REMEDIATION_WORKER_SHARED_SECRET, and DATA_REMEDIATION_PRODUCTION_URL, then runs npx tsx scripts/data-remediation-dev-runner.ts with the claimed job serialized as JSON.
This gives VibeChopper a clean separation of responsibilities. The outer worker polls and dispatches. The server owns claim state and callback verification. The dev runner owns the actual repair attempt. The public tracker owns the readable progress view. No part has to pretend to be the whole system.
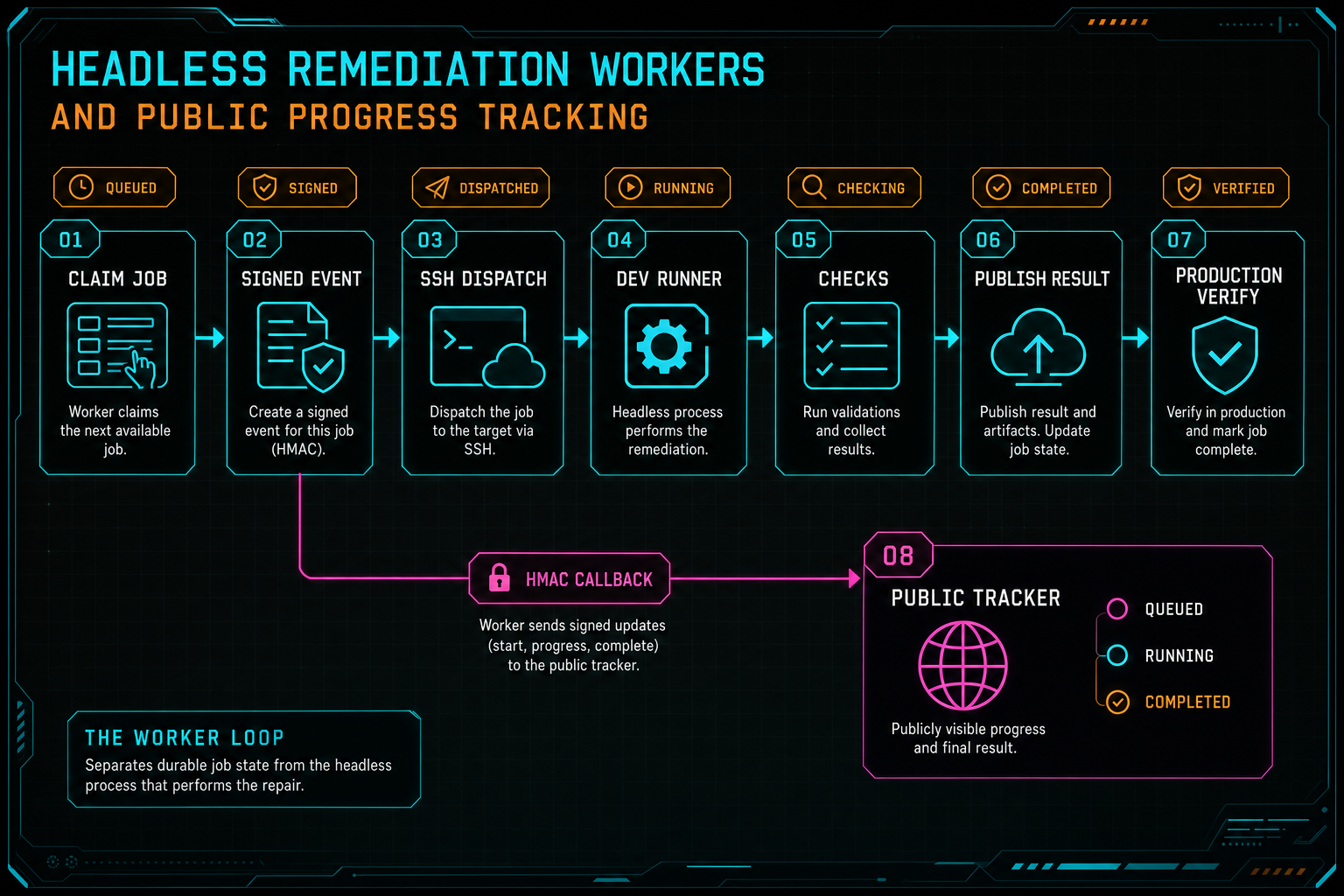
The worker loop separates durable job state from the headless process that performs the repair.
Signed Events Feed Public Progress
Progress tracking starts with callbacks. Both the worker and the dev runner use signed POST requests when they report events. The callback body is serialized as JSON, paired with a timestamp, and signed with HMAC-SHA256. The server verifies the timestamp and signature before it lets the event mutate remediation state. That is why the tracker can show background worker progress without trusting anonymous internet traffic. Send feedback with context
The event vocabulary is intentionally concrete. The outer worker reports dispatch start and dispatch finish. The dev runner reports agent_attempt_started, agent_attempt_finished, agent_attempt_error, and production_verified. Completion and publish results go through dedicated worker endpoints. Each event can carry a payload with attempt number, wave, provider, prompt path, command summary, checks, AI verification, publish metadata, or production verification.
The public tracker does not render raw terminal output as the product experience. It translates job status and event payloads into a bounded status model. A submitter sees phases like Received, Planning, Building, Checking, Publishing, and Live. Workers can add phase titles, wave details, agent names, rubrics, plans, and verification summaries when useful. The route clamps and slices the public payload so the tracker remains informative without becoming a dump of internal logs.
That public/private split is the useful part. Internally, the job preserves the detail needed to debug and audit repair work. Publicly, the submitter gets a plain account of what is moving. VibeChopper uses this same pattern in other long-running systems: upload sessions have telemetry, render pipelines have verification records, AI edit runs have tool events, and remediation jobs have signed progress events.
The public tracker translates worker events into phases that make sense to a submitter.
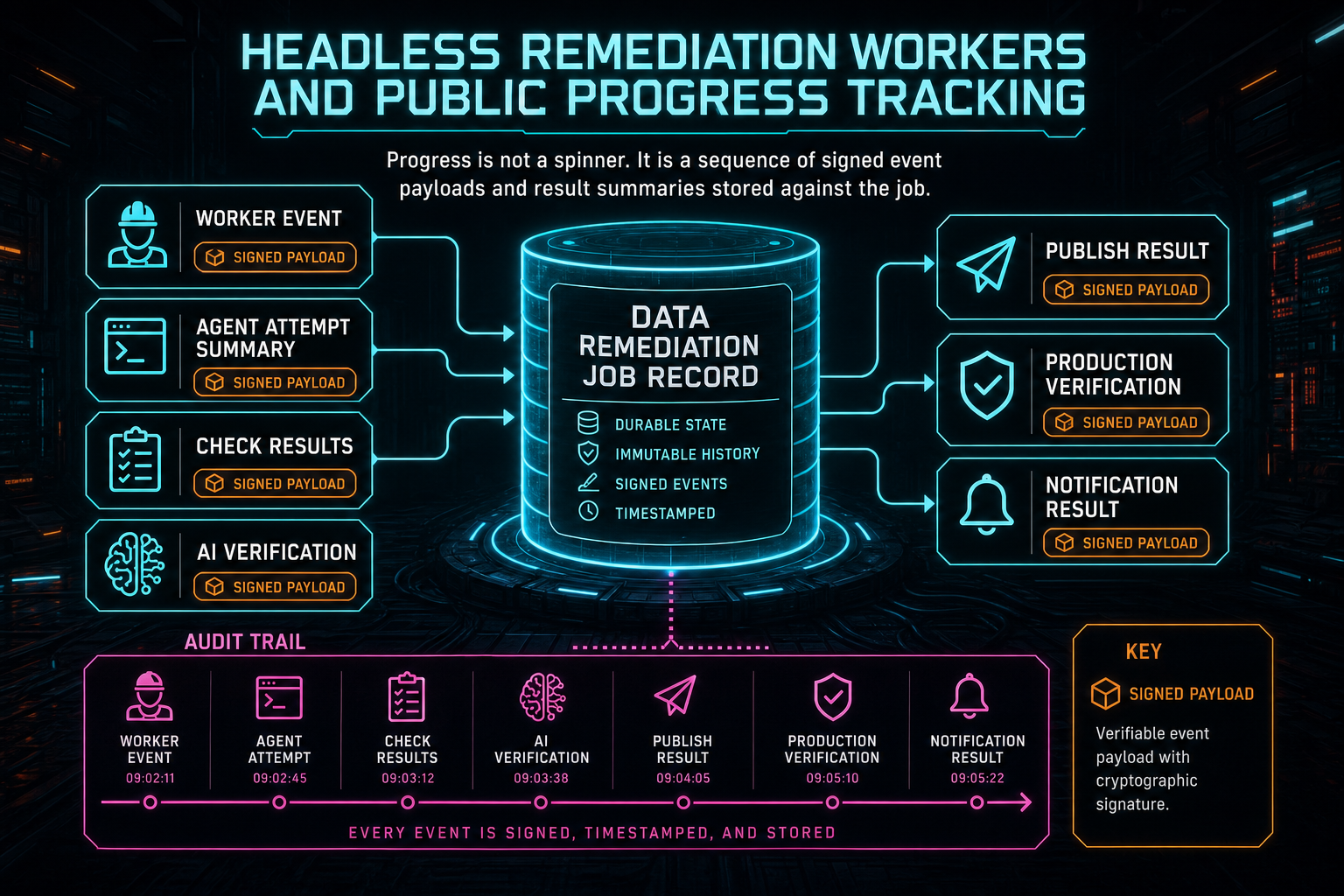
Progress is not a spinner. It is a sequence of signed event payloads and result summaries stored against the job.
Inside the Dev Runner
scripts/data-remediation-dev-runner.ts is where the repair becomes executable. It builds a prompt file in a temp directory, chooses an agent provider, runs the agent command, runs checks, runs two AI verification passes, commits and pushes when appropriate, publishes through the adapter, verifies production, and reports the result back to the server.
The prompt is deliberately explicit. It includes the job ID, source type, source ID, attempt number, raw incident context, sanitized user request, classification, allowed file scopes, repository instructions, approval mode, three-attempt strategy, callback API notes, verification expectations, and final report expectations. It tells the agent to read AGENTS.md and CLAUDE.md, to work in the normal shared tree, to avoid creating worktrees or workflow files, to avoid managing the Replit dev server, and to use the repository's existing stack.
The three-attempt strategy is important because repair automation should not blindly repeat the same failure. Attempt one asks for the smallest coherent fix supported by evidence. Attempt two broadens investigation to adjacent contracts, route/client/server boundaries, cache, auth, persistence, and integration assumptions. Attempt three asks for a conservative fallback or containment before escalation. That gives the agent a clear operating model without pretending every issue has an instant patch.
The runner can use Codex, Claude, or a custom command. Auto mode prefers codex when available, then claude, and otherwise requires a custom command. Codex receives the prompt on stdin with full workspace access. Claude receives a print-mode prompt with permission bypass. Custom commands also receive prompt stdin. That provider flexibility keeps the remediation system from depending on one headless agent binary while preserving the same job and callback contract.
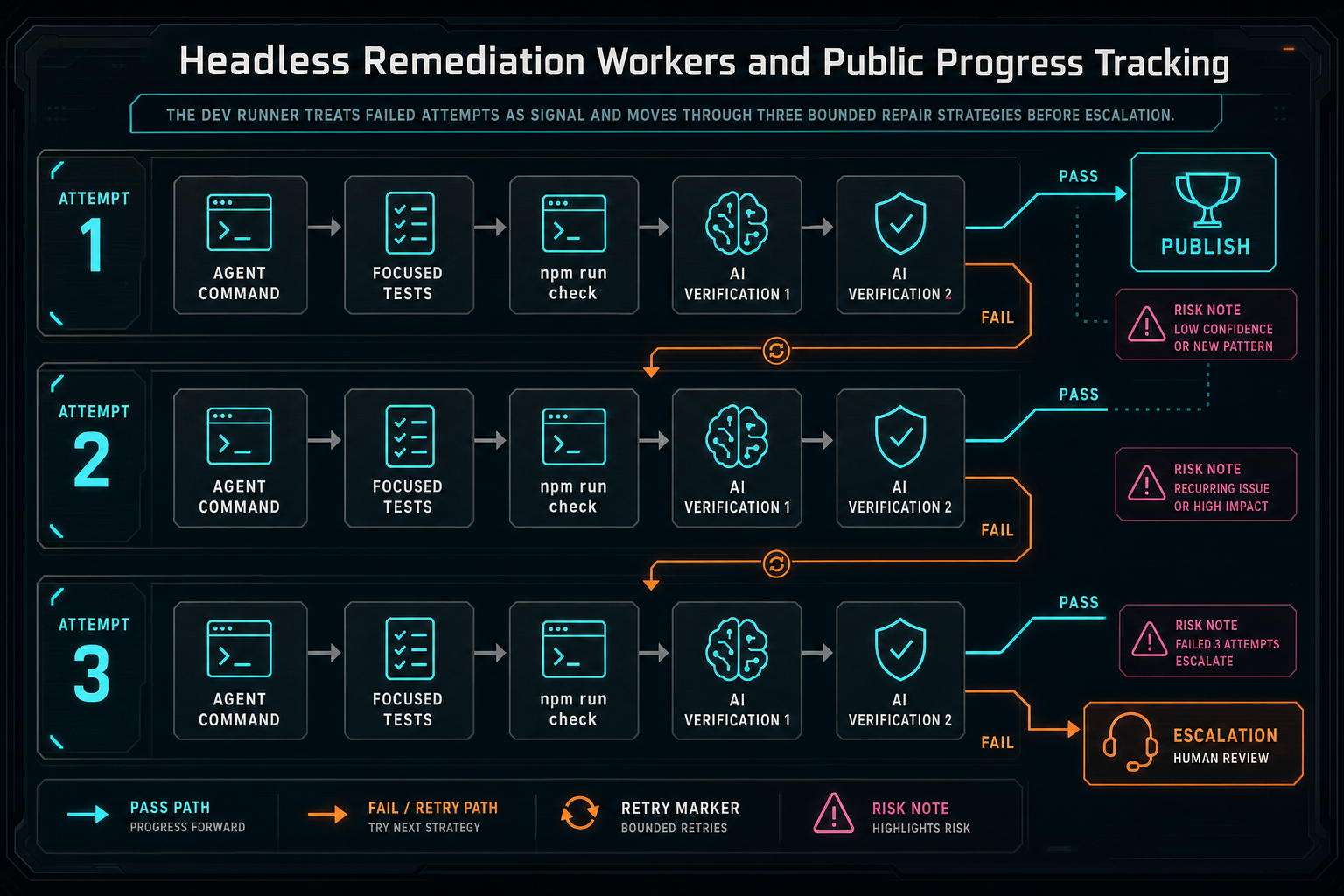
The dev runner treats failed attempts as signal and moves through three bounded repair strategies before escalation.
Checks, Verification, and Publish
A repair is not complete just because an agent process exits with code zero. The dev runner runs checks next. By default, it runs npm run check, npm run lint, and npm run build, unless DATA_REMEDIATION_CHECK_COMMANDS overrides the list. It stops on the first failed check and records command, code, stdout, and stderr in a truncated summary so the job record stays useful without storing unbounded output. Upload a real shoot
After checks, the runner executes two AI verification commands. The defaults are placeholders, but the contract is there: two independent verification passes can inspect the job ID and attempt number, and failure blocks publishing. This is the same engineering posture behind VibeChopper's AI edit infrastructure. Agents can propose and execute work, but the product needs artifacts, checks, and verification before declaring the result good.
When the agent command, checks, and verification pass, the runner commits and pushes in normal mode. In dry-run mode, it returns the current HEAD instead. Then it posts /api/data-remediation/worker/:id/complete with awaiting_publish, branch name, commit SHA, and check results. The publish adapter runs next. Its result is posted to /api/data-remediation/worker/:id/publish-result.
The final step is production verification. If the publish result is published, the runner performs a GET against the production URL and emits production_verified with status details. If the publish result is skipped in dry-run mode, the runner records a synthetic successful verification that explains the skip. If production verification fails, the runner continues through the remaining attempts instead of pretending a broken deployment is live.
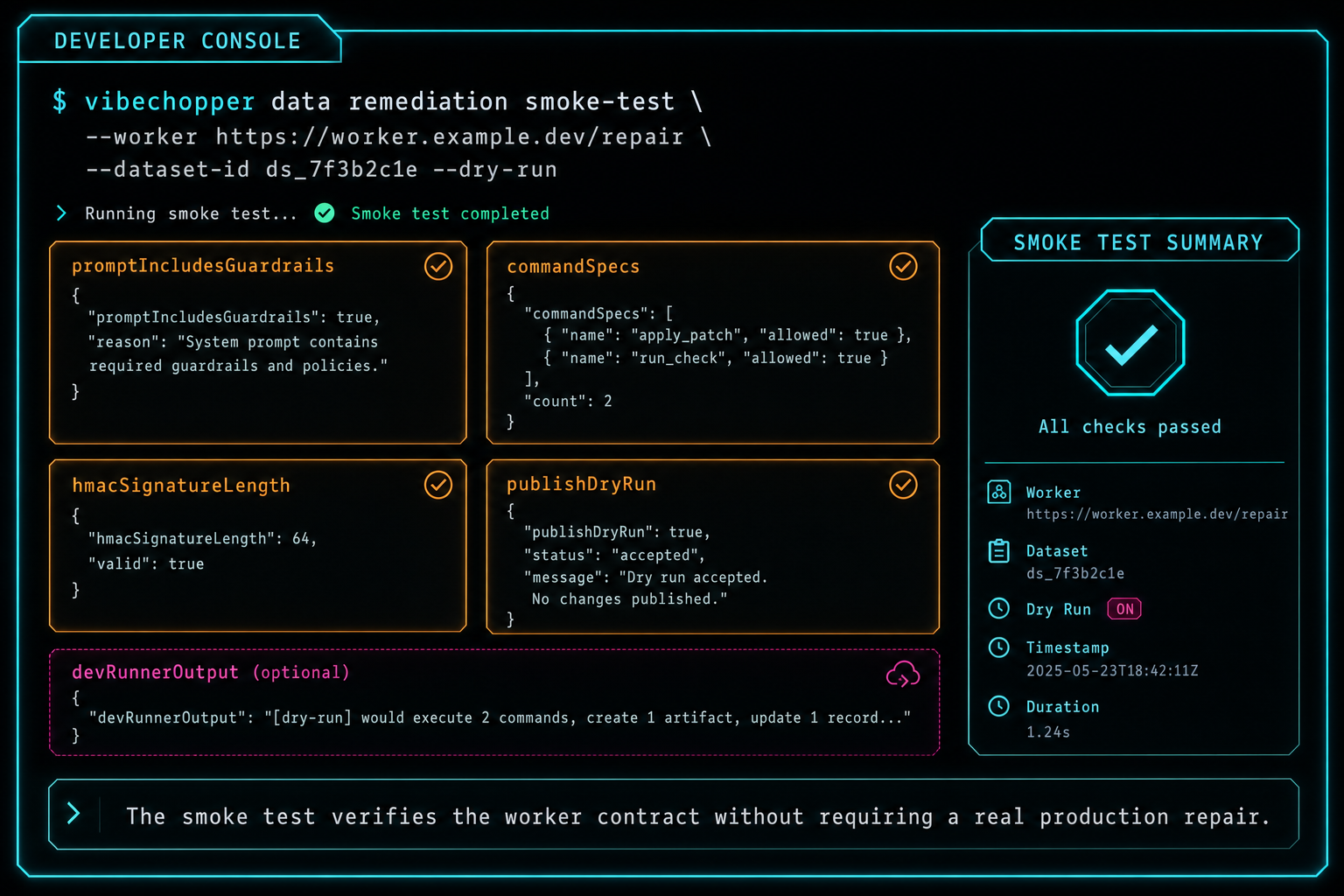
The smoke test verifies the worker contract without requiring a real production repair.
Smoke Testing the Contract
scripts/data-remediation-smoke-test.ts exists to validate the worker system without needing a real incident to break production. It builds a smoke job, exercises prompt generation, constructs command specs for Codex, Claude, and custom providers, checks HMAC signature length through callbackSignature, and runs a publish dry run through the adapter. With --run-dev-runner, it also runs a no-op custom-agent dev runner dry run.
That smoke test catches a specific class of failure: contract drift. If prompt guardrails stop including the server-management rule, the smoke output exposes it. If command construction stops passing the prompt on stdin, the command spec summary exposes it. If callback signing stops producing a 64-character SHA-256 hex digest, the HMAC check exposes it. If publish dry-run behavior changes, the adapter result exposes it.
This is focused verification, not a replacement for route tests, integration tests, or production monitoring. Its value is speed and scope. A developer can ask whether the headless remediation machinery still knows how to form prompts, choose providers, sign callbacks, and dry-run publish behavior. Those are the seams that background repair depends on.
The smoke test also documents the supported extension points. A team can plug in a custom agent command through DATA_REMEDIATION_AGENT_COMMAND, override check commands through DATA_REMEDIATION_CHECK_COMMANDS, and run dry mode with DATA_REMEDIATION_DEV_RUNNER_DRY_RUN and DATA_REMEDIATION_PUBLISH_DRY_RUN. The workflow is headless, but it is not opaque.
Design Lessons
The first lesson is to make the durable job the source of truth. A headless worker is a process. It can crash, lose stdout, restart, run once, poll forever, or exhaust attempts. The job record survives those conditions. It holds status, source context, allowed scope, runner status, check results, publish result, notification result, and recent events. Open the edit-run receipts
The second lesson is to separate execution from explanation. The worker and dev runner execute repair work. The public tracker explains progress. That lets VibeChopper keep the tracker readable even when the underlying operation has many moving parts: SSH dispatch, agent command, tests, AI verification, commit, publish adapter, production URL verification, and notification.
The third lesson is to sign the progress channel. Public progress tracking is valuable only when the product can trust the updates. HMAC callbacks are not an optional flourish around remediation; they are the boundary that lets background processes report state while the server remains the owner of mutation.
The fourth lesson is to reuse observability patterns across product surfaces. Video uploads, media processing, AI edit runs, renders, and remediation repairs all have the same shape: long-running work, user-visible consequences, partial failure modes, retry behavior, and durable artifacts. VibeChopper treats those as product events, not console logs. That is why a creator can upload footage with progress they can trust, inspect an AI edit run, and report feedback into a visible repair loop.
What Developers Should Copy
If you are building automated remediation for your own product, start with the queue and tracker, not the agent. Define a durable job with source identity, public status, internal status, allowed scope, sanitized prompt, redacted context, lock fields, attempts, checks, publish result, and notification result. Then make your worker claim jobs through a narrow endpoint instead of giving it broad database access.
Make callbacks signed, typed, and small. A worker should be able to report that an attempt started, that checks failed, that publishing finished, or that production verification passed. It should not need a generic mutation tunnel. Authenticate the callback, validate the payload, append the event, and let server-owned status logic decide what the public sees.
Give the headless runner an operating rubric. VibeChopper's runner tells agents how to behave across three attempts, which repository instructions to obey, which commands to run, what not to touch, and how to report results. That explicit contract matters more than the particular agent provider. Codex, Claude, or a custom command can all be useful when the surrounding job system keeps them inside a product workflow.
Finally, make the user's status page honest. Do not show a fake progress bar. Show phases derived from durable state. If checks failed, say the repair is checking or needs another attempt. If publish is skipped in dry-run mode, record that. If production verification fails, do not send a live-fix notification. Users do not need every internal detail, but they do deserve a tracker that reflects real state.
The Result
Headless remediation workers give VibeChopper a way to move production repair outside the user's request without losing accountability. A creator reports feedback. The product creates a remediation job. A worker claims it, reports dispatch, runs the dev runner, emits attempt events, records checks, publishes when ready, verifies production, and updates the public tracker along the way.
The system is technical because the promise is concrete. Feedback should not vanish into a support inbox. Agent repair should not vanish into a terminal. Public progress should not be based on optimistic browser state. DATA Remediation keeps the chain durable: job, event, check, publish result, production verification, notification.
That is the same VibeChopper pattern applied to reliability work. The editor helps creators describe video edits by voice, vibe, and timeline context. The platform around the editor applies the same discipline to repairs: preserve context, run the work, verify the result, and keep the trail visible. When the fix is live, the user can see how it got there.
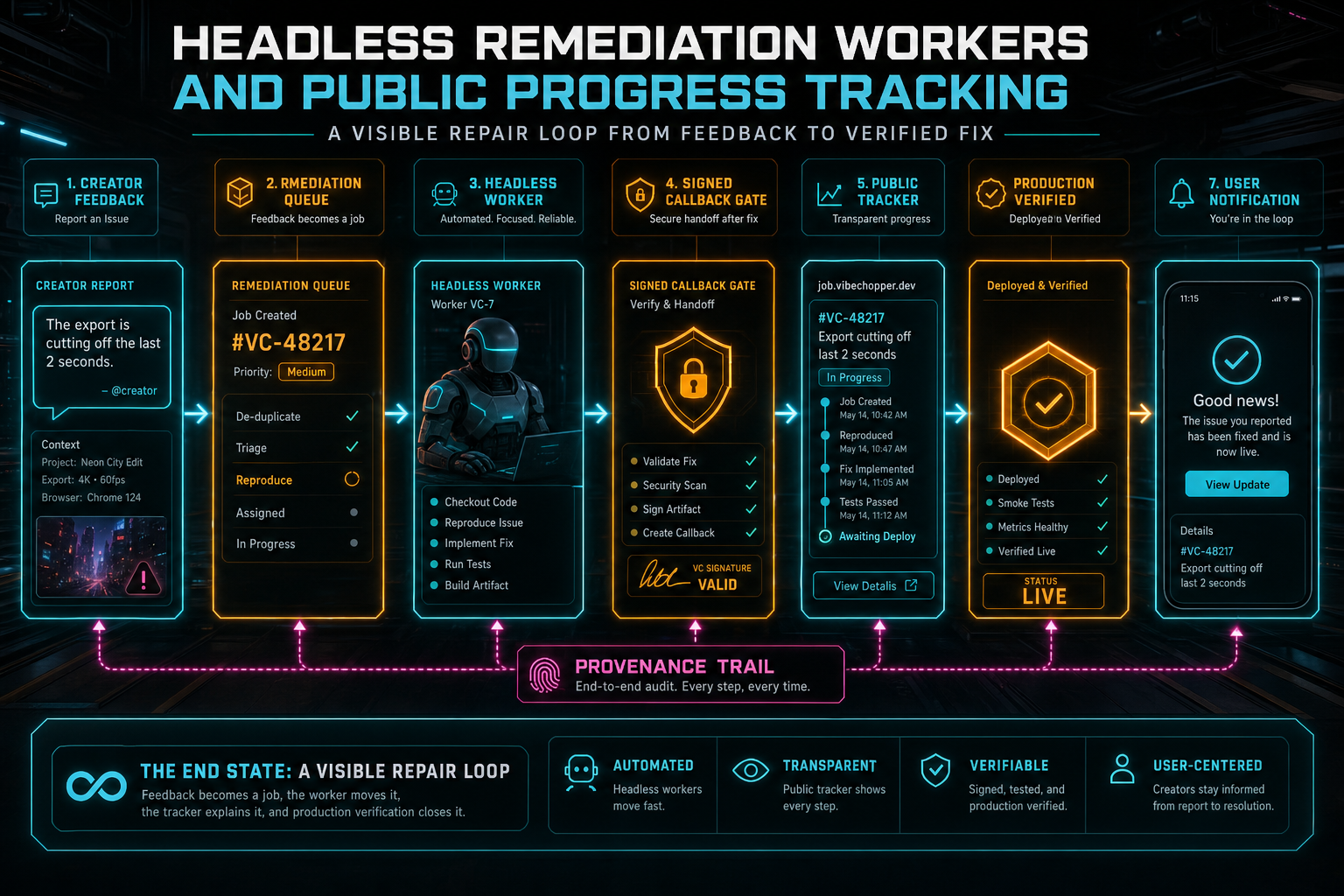
The end state is a visible repair loop: feedback becomes a job, the worker moves it, the tracker explains it, and production verification closes it.
Try the workflow
Open every feature from this post in the editor
These panels collect the features discussed above. Sign in once, finish your profile if needed, then the editor opens the first highlighted surface and walks through the tutorial.
Step 1
Send contextual feedback
Capture voice or written feedback with project context so issues can become repairable jobs.
Send feedback with context →Step 2
Inspect an AI edit run
Open the editor and see how plans, tool calls, artifacts, and render results stay connected.
Open the edit-run receipts →Step 3
Upload footage with progress you can trust
Watch large video uploads, processing, transcript work, and original-file storage from one monitor.
Upload a real shoot →Step 4
Create a secure editing account
Use email bootstrap and passkeys to get into the editor without password friction.
Create your editing login →